

How to Analyse Google Discover
Whilst Discover data is limited, we can build propriety internal systems that help us get so much more out of the platform

TL;DR
To generate the most value from Discover, view it through an entity-focused lens. People, places, organisations, teams et al.
Your best chance of success in Discover with an individual article is to make sure it outperforms its expected performance early. So share, share, share
Then analyse the type of content you create. What makes it clickable? What resonates? What headline and image combination work?
High CTR is key for success, but ‘curiosity gap’ headlines that fail to deliver kill long-term credibility. User satisfaction trumps clickiness over time.

Discover isn’t a completely black box. We have a decent idea of how it works and can reverse engineer more value with some smart analysis.
Yes, there’s always going to be some surprises. It’s a bit mental at times. But we can make the most of the platform without destroying our credibility by publishing articles about vitamin B12 titled:
‘Outlive your children with this one secret trick the government don’t want you to know about.’
This kind of curiousity gap is killing your site’s credibility. With the algorithm and you know, real people. As John Shehata would say, be clicky, not baity.
We consult on all things AI risk and resilience, the future of search, your market positioning and approach to audience targeting. Our consulting website is here - if you need help, get in touch.
Key tenets of Discover
Before diving in headfirst, let’s check the depth of the pool.
Search and Discover are intrinsically linked. Google has admitted this at their Zurich Search Central conference
“Sustained presence on search helps maintain your status as a trustworthy publisher”
Discover feeds off fresh content. Whilst evergreen content pops up, it is very closely related to the news.
More lifestyle-y, engaging content tends to thrive on the clickless platform.
Just like news, Discover is very entity, click and early engagement driven.
The personalised platform groups cohorts of people together. If you satiate one, more of that cohort will likely follow.
If your content outperforms its predicted early stage performance, it is more likely to be boosted.
Once the groups of potentially interested doomscrollers have been saturated, content performance naturally drops off.
Google is empowering our ability to find individual creators and video content on the platform, because people trust people and like watching shit. Stunned.
Obviously loads of people know how to game the system and have become pretty rich by doing so. If you want to laugh and cry in equal measure, see the state of Google’s spam problems here.

Most algorithms follow the Golden Hour Rule. Not to be confused with the golden shower rule, it means the first 60 minutes after posting determine whether algorithms will amplify or bury your content.
If you want to go viral, your best bet is to drive early stage engagement.
If you want a video take on where Discover is going, you’re in luck:
What datapoints should you analyse?
This is focused more on how you as an SEO or analyst can get more value out of the platform. So let’s take conversions and click/impression data as read. We’re going deeper. This isn’t amateur hour.
I think you need to track the below and I’ll explain why.
CTR
Entities
Subfolders
Authorship
Headlines and images
Content type (just a simple breakdown of news, how-tos, interviews, evergreen guides etc)
Publishing performance
You need to already get traffic from Discover to generate value form this analysis. If you don’t, revert back to creating high-quality, unique content in your niche(s) and push it out to the wider world.
Create great content and get the right people sharing it.
Worth noting you can’t accurately identify Discover traffic in analytics platforms. You have to accept some of it will be mis-attributed. Most companies make an educated guess of sorts, using a combination of Google and mobile/android to group it together.
CTR
CTR is one of the foundational metrics of news SEO, Top Stories, Discover and almost any form of real time SEO. It is far more prevalent in news than traditional SEO because the algorithm is making decisions about what content should be promoted in almost real time.
Evergreen results are altered continuously, based on much longer-term engagement.
This is weighted alongside some kind of traditional Navboost engagement data - clicks, on page interactions, session duration et al - to associate a clickable headline and image with content that serves the user effectively.
It’s also one of the reasons why clickbait shit has (broadly) started to die a death. Like rampant AI slop, even the mouth breathers will tire of it eventually.
To get the most out of CTR, you need to combine it with;
Image type
Headline type (content type too)
And entity analysis
Entity analysis
Entities are more important in news than any other part of SEO. Whilst entity SEO has been growing in popularity for years, news sites have been obsessed with entities (arguably without knowing it), for years.

Whist it isn’t as easy to just frontload headlines with relevant entities to get traffic anymore, there’s still an real value from analysing performance at an entity level.
Particularly in Discover.
You want to know what people, places and organisations (arguably these three make up 85%+ of all entities you need to care about) drive value for you and users in Discover.
To run proper entity analysis you cannot do this manually. At least not well or at scale.
My advice is to use a combination of your LLM of choice, an NER (Named Entity Recognition) tool and either Google’s Knowledge Graph or WikiData.
You can then extract the entity from the page in question (the title), disambiguate using the on page content (this helps you assess whether ‘apple’ is the computing company, the fruit or an idiotic celebrities daughter) and confirm it with WikiData or Google’s Knowledge Graph.

Subfolder
Relatively straightfoward, but you want to know which subfolders tend to generate more impressions and clicks on average in Discover. This is particularly valuable if you work on larger sites with a lot of subfolders and high content production.

You want to make sure that everything you do maximises value.
This becomes far more valuable when you combine this data with the type of headline and entities. If you begin to understand the type of headline (and content) that works for specific subfolders, you can help commissioners and writers make smarter decisions.
Subfolders that tend to perform better in Discover give individual articles a better chance of success.
Generate a list of all of your subfolders (or topics if your site isn’t setup particularly effectively) and tracking clicks, impressions and CTR over time. I’d use total clicks, impressions and CTR and an average per article as a starting point.
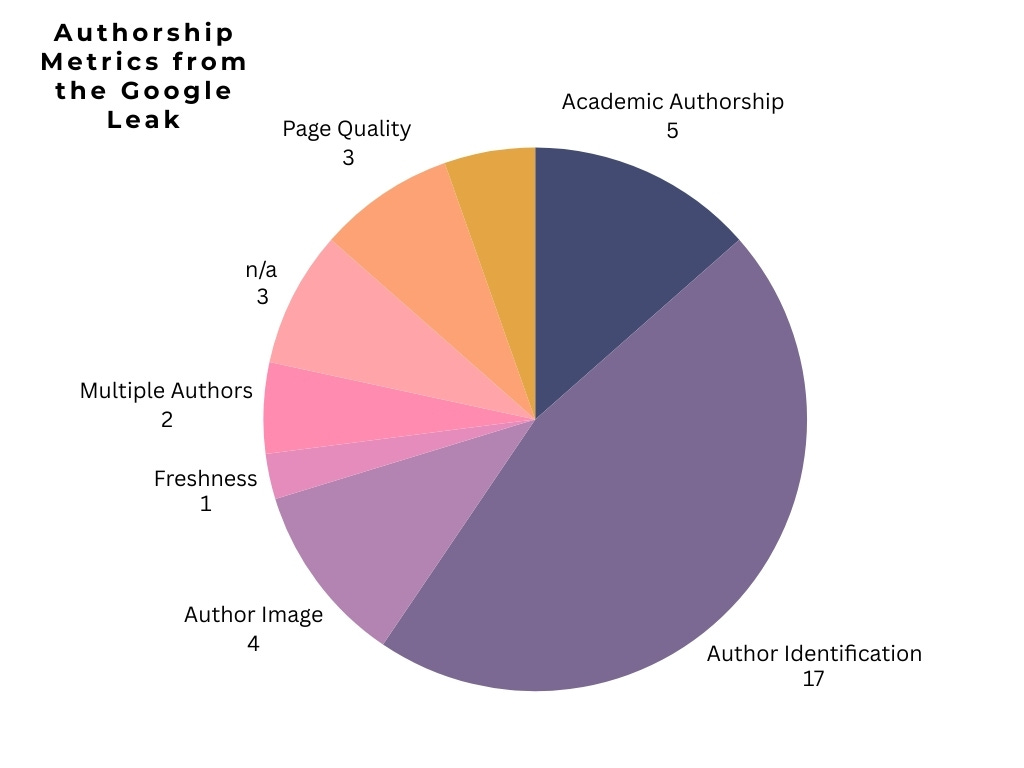
Authorship
Google tracks authorship in search. No ifs, no buts. The person who writes the content has significance when it comes to EEAT and good, reliable authorship makes a difference.
How much significance, I don’t know. And neither do you.
In breaking down all metrics from the leak that mention the word ‘author,’ the below is a how Google perceives and values authorship. As always, this is an imperfect science, but it’s interesting to note that of the 35 categories I reviewed, almost half are related just to identifying the author.
Disambiguation is one of the most important components of modern day search. Semantic SEO. Knowledge graphs. Structured data. EEAT. A huge amount of this is designed to counter false documents, AI slop and misinformation.
So it’s really important for search (and Discover), that you provide undeniable clarity.
For Discover specifically, you should see authors through the prism of:
How many articles have they written that make it onto Discover (and that perform in Search)?
What topic/entities do they perform best with?
Ditto headline type
Headline type
This is a really good way of viewing the type of content that tends to perform for you. For example, you want to know whether curiousity gap headlines work well for you and whether headlines with numbers in have a higher or lower CTR on average.
Do headlines with celebrities in the headline work well for you?
Does this differ by subfolder?
Do first person headlines have a higher CTR in Money than in News?
These are all questions and hypotheses that you should be asking. Although you can’t scrape Discover directly (trust me I’ve tried), you can hypothesise which h1, page title and OG title is the clickiest.

What’s interesting in this example is that ‘how-to’ headlines are not portrayed as very Discover-friendly. But it’s the concept that sells it. It’s different.
Start by defining all the types of headlines you use - curiousity gap, localised, numbered lists, questions, how-to or utility type, emotional trigger, first person et al - and analyse how effective each one is.
Use a machine learning model (you can absolutely use ChatGPT’s API) to categorise each headline.
Train the model to identify place names, numbers, questions and first-person style patterns
Verify the quality of the categorisation
Break this down by subfolder, author, entity or anything else you choose
Worth noting that there are five different headlines you and Google can and should be using to determine how content is perceived. Discover is known to use the OG title more frequently than traditional search.
It’s an opportunity to create a ‘clickier’ headline than you would typically use in the h1 or page title.
Images
Images fall into a similar category as headlines. They’re crucial. You can’t definitively prove which image gets pulled through into Discover. But as long as your featured image is 1200px wide, it’s safe-ish to assume this is the one that’s used.
CTR is arguably the single biggest factor in determining early success. Continued success I believe is more Navboost related - more traditional-ish engagement.
And CTR in Discover is determined by two things:
The headline
The image
Well, two things in your control. You could be pedantic and say ooo your brand is an important factor in CTR actually. Psychologically people always click on…
And I’d tell you to bore off. We’re talking about an individual article. We’ve done a significant amount of image testing and know that in straight news, people like seeing people looking sad. They like real-ness.
In money, they like people looking at the camera looking happy. It makes them feel safe in a financial decision.

Stupid, I know. But we’re not an intelligent race. Sure, there’s a few outliers. Galileo. Einstein. Noel Edmonds. But the rest of us are just trying not to throw shit at each other outside Yates’s on a Friday night.
It is actually why clickbait headlines have worked for years. It works until it doesn’t.
You’ll need to upload a set of images to help train the model and please for Christ’s sake don’t take it as gospel. Check the outputs. For the basics - whether people are present, where they’re looking, colour schemes etc - great. For more nuanced decisions like trustworthiness or emotional meaning, you’ll need to do that yourself.
Worth noting that lots of publishers trial badges and logos on images. And for good reason. Images with logos consistently click higher for larger brands (to the best of my knowledge) and if you’re a paywalled site, but have set live blogs to free, it’s worth telling people.
You should breakdown this image analysis into;
Human presence and gaze
Facial expression
Emotional resonance
Composition and framing
Colour schemes
Photo-type
Then you can use machine learning to bucket photos into groups to help determine CTR. For example, people directly looking at a camera + smiling could be one bucket. Not looking at a camera + scowling.
Publishing Performance
The more you publish, the more this matters.
Large newsrooms run analysis on publishing volumes, times and content freshness fairly consistently and at a desk-level. If you only have 50 or fewer articles per month making it into Discover, you probably don’t need to do this.
But if we’re talking about hundreds or thousands of articles, these insights can be really useful to commissioners.
I would focus on;
Publishing days
Publishing times
Content freshness
Republishing vs publishing



Your output should give really clear guidance to desks, commissioners and publishers around when is best to publish for peak Discover performance.
We never make direct recommendations solely for Discover for a number of reasons. Discover is a highly volatile platform and one that does reward nonsense. It can lead you down the garden path with all sorts of thin, curiousity gap style content if you just follow the numbers.
And it has limited direct impact on your bottom line.
How do you tie this all together?
You need a clear set of goals. Goals that help you deliver analysis that directly impacts the value of your content in Discover. When your set your analysis. focus on elements you have more control over.
For example, you might not be able to control what commisioners choose to publish, but you can change the headline (h1, title and/or OG) and image prior to publish.
Set a clear goal around conversions and traffic
Understand what you have more control over
Deliver insights at a desk or subfolder level
Understanding whether your role is more strategic or tactical is crucial. Strategic roles are more advisory in nature. You can offer some thoughts and advice on the type of headlines and entities to avoid or choose, but may not be able to change them.
Tactical roles mean you have more say in the implementation of change. Headlines, publish times, entity targeting etc.
Simple.
Some other goodies on this topic
That’s it, here’s some other cool stuff about Discover.
Unlocking Google Discover by John Shehata
Top 12 Ways to Optimize For Google Discover in 2025 by Metehan Yeşilyurt
How To Succeed In Google Discover by Abby Hamilton